DevOps for Data Scientists
Part 1: Introductions, setup, & workshop overview
Meet your instructors
Director of Posit Strategy, former Solutions Engineer
David Aja is a Solutions Engineer at Posit. Before joining Posit, he worked as a data scientist in the public sector.
Gagandeep Singh is a former software engineer and data scientist who has worked in a variety of cross-technology teams before joining Posit as a Solutions Engineer.
Scientist by training turned IT / HPC / Scientific Computing
Solutions Engineering at Posit
Posit’s Solutions Engineering team aims to shrink the distance between the needs of Posit’s customers and our Pro and Open Source offerings, leading with curiosity and technical excellence.
Our customer-facing work helps our customers deploy, install, configure, and use our Pro products.
Introduce yourself to your neighbor
Take 5 minutes and introduce yourself to your neighbors.
Word Cloud
💻 If your WIFI isn’t working let us know as soon as possible!
Name: Posit Conf 2023
Password: conf2023
Documentation & Communication
All documents including slides are available on our website: https://posit-conf-2023.github.io/DevOps/
Discord channel - devops-for-data-scientists
During labs and exercises,please place a post-it note on the back of your laptop for:
🟥 - I need help
🟩 - I’m done
Daily Schedule
📅 September 17 and 18, 2023
⏰ 09:00am - 5:00pm
10:30 - 11:00am
Break
12:30 - 1:30pm
Lunch
3:00 - 3:30pm
Break
Code of Conduct
Everyone who comes to learn and enjoy the experience should feel welcome at posit::conf. Posit is committed to providing a professional, friendly and safe environment for all participants at its events, regardless of gender, sexual orientation, disability, race, ethnicity, religion, national origin or other protected class.
This code of conduct outlines the expectations for all participants, including attendees, sponsors, speakers, vendors, media, exhibitors, and volunteers. Posit will actively enforce this code of conduct throughout posit::conf.
https://posit.co/code-of-conduct/
Workshop Goals
To understand how DevOps can help you in your work as data scientists
To understand the main principles and tools of DevOps
To get hands-on experience putting code into production using common DevOps workflows
To leave the workshop with some “assets” and skills you can use in your work
Most important Linux commands
cd change directory
https://linuxize.com/post/linux-cd-command/
ls list all files in current working directory;
add -lha flag for hidden files
https://linuxize.com/post/how-to-list-files-in-linux-using-the-ls-command/
pwd print working directory
https://linuxize.com/post/current-working-directory/
touch create a file
https://linuxize.com/post/linux-touch-command/
mkdir create a directory
https://linuxize.com/post/how-to-create-directories-in-linux-with-the-mkdir-command/
vim open a file in Vim text editor
https://linuxize.com/post/how-to-save-file-in-vim-quit-editor/
curl command-line utility for transferring data from or to a server. Uses one of the supported protocols including HTTP, HTTPS, SCP , SFTP , and FTP
https://linuxize.com/post/curl-command-examples/
echo print argument to standard output
https://linuxize.com/post/echo-command-in-linux-with-examples/
$PATH environmental variable that includes colon-delimited list of directories where the shell searches for executable files
https://linuxize.com/post/how-to-add-directory-to-path-in-linux/
Section Goals
To understand the main principles of DevOps and how they can improve data science workflows.
To get familiar with the DevOps toolkit .
To get familiar with how the renv
To get comfortable using the terminal for interacting with git and github .
To understand how to authenticate to github using SSH or HTTPS.
To practice creating a CI/CD workflow using yaml and Github Actions.
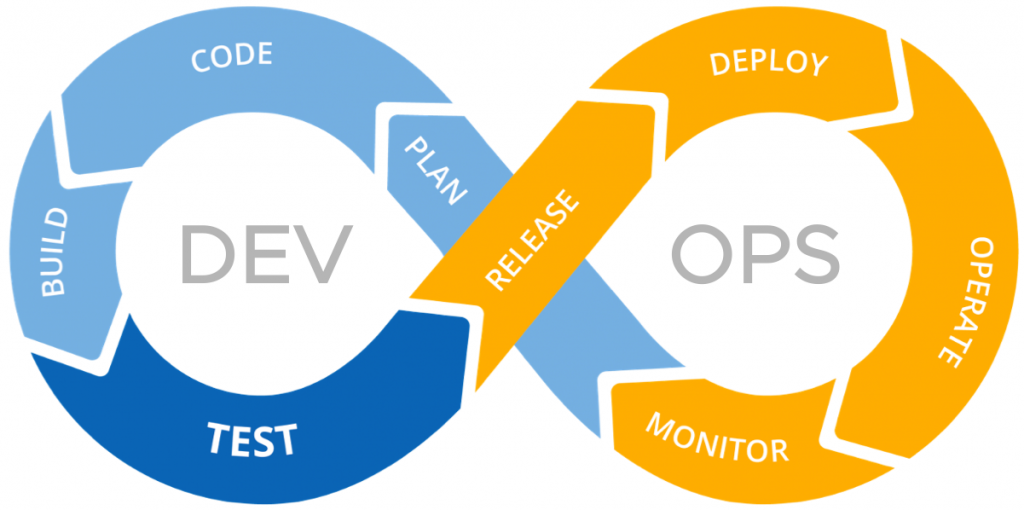
“DevOps is a set of cultural norms, practices, and supporting tooling to help make the process of developing and deploying software smoother and lower risk.”
Let’s get into it. We’re at a DevOps workshop - so what is it. This is a best effort attempt by our very own Alex Gold, but its still a squishy broad buzz word that’s defined differently across organization. Let’s discuss how the concept of devops came about.
But first…a very brief history lesson
Reason for squishy definition is because it developed organically in the 2007-2009, across social media, twitter tag #devops was popular, online communities and became more organized through conferences, workshops, and grassroots attempts at implementation at diff companies. Then was introduced into larger companies like Intel, PayPal, Facebook.
Became more popular through work by Gene Kim and Patrick Debois and others - Pheonix Project is actually a novel about an IT project at a made-up company.
So what were all these people trying to do - what was the context? All trying to create something.
So you want to create an app?
Let’s talk about what it looks like to create an application. On one side you had developers creating some sort of application - let’s say a stock trading application, so your end user are stock traders
Devs would work on creating the code for this app, get requirements, test it and then package up all the source code in some way so that its executable and that it could be deployed somehow to those end users you’d configure the server, install any tools and frameworks needed to run the code, and then launch.
Now your stock traders are using their application - maybe they’re giving feedback somehow or errors are being logged. Another team is monitoring the environment and seeing if servers are able to handle the load of all the users.
But eventually you’d need to fix bugs or release new features or maybe change things so that the app could handle more end users -
your dev team make updates, version those changes, test them, re-launch the app and you do this over and over again in some sort or release process – so you have this continuous cycle of releasing your app, finding something to fix or add, testing that change, integrating that code, and then releasing the app..
Making this continuous process as fast, efficient, accurate, and low risk is the goal of devops.
sounds pretty efficient right -
Problems DevOps tries to solve
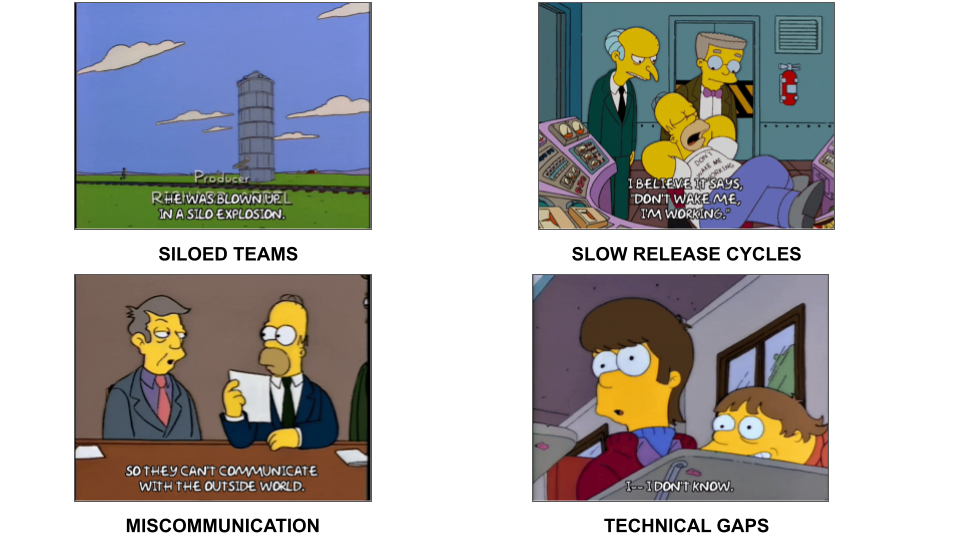
So this is the idealized example - but what was it like in practice 20 years ago. You want to make the release process as fast as possible but you also want it to be tested and free of bugs. And this introduces a natural conflict between speed and stability
You have the same goals of speed and accuracy - but this process of continuous integration, of testing, of automating processes so that your users can get their hands on the app - didnt exist.
One problem is that the entire process is siloed between the creation of the code and the deployment of your app. So your developers finish their code and then throw it over the fence to ops. Maybe they then throw it to security or to QA. But there was no formal alliance in place or processes on how the teams work together. Because each team is seemingly working on one part - the code vs. the deploy - there’s also technical knowledge siloes - each team only knows their bit but not anything else.
So imagine this stock trading app - your developers are creating cool new features so that you can easily buy and sell stock, maybe even see data on whats happening in the market. But they’re not necessarily thinking about how the app is secured or if its compliant with federal regulations or if user data is protected. Obvi this is a worst case scenario - but you get the picture.
So as the app is built it keeps getting thrown back and forth between the two teams and leads to one of the major problems that devops is trying to fix - really slow and manual bureaucratic release process.
On the technical side, a lot of the actual work is done manually. So you can imagine one team running tests manually in one environment - maybe the environment itself is created manually, or someone manually sizing up or fixing a server. This takes time, you need to get approval from people, and its not easily reproduced or really documented anywhere. Also, there is a lot of room for error and if things break its not easy to roll back bugs.
Problem becomes how do you automate this release process, make it streamlined, less error prone, improve how all these teams integrate and operate, and at the end of the day make the process of getting the app into the hands of your users much faster.
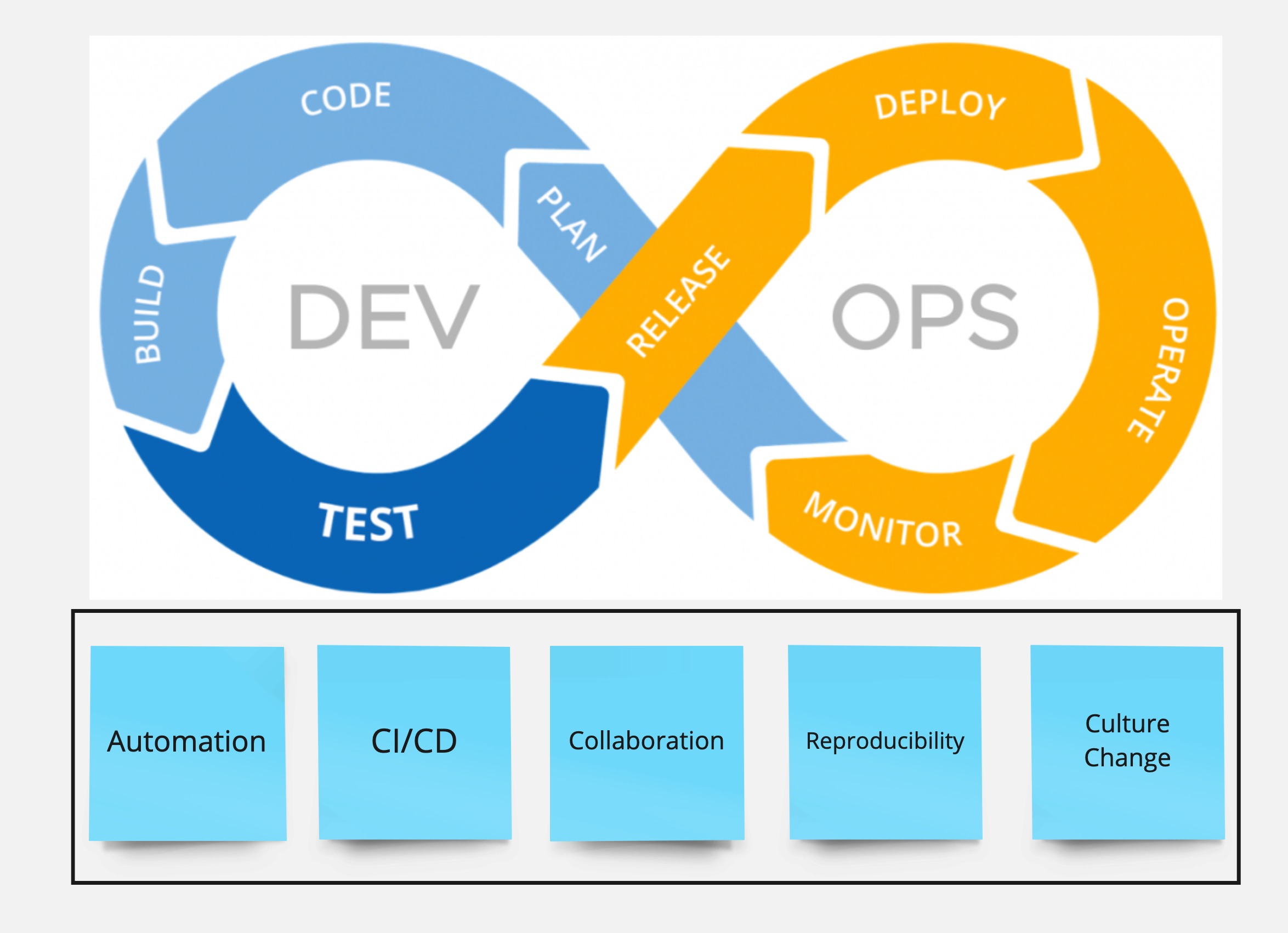
Common DevOps Principles
🤲 Collaboration
🚚 Continuous Integration & Delivery
🤖 Automation
📔 Reproducibility
👨🎤 Culture change
As the field of devops developed, there are different implementations/diff technologies of what devops means - these happen differently at different companies But there have been some common philosophies and best practices that have come out that I’ve seen consistently across the entire ecosystem.
First - everyone that’s involved in the creation of this application should be collaborating and working together. This is my wink wink moment for you all of why devops is so important for data scientists
Then we have this concept of Continuous Integration & Delivery - we’ll take about this in greater length in a few minutes - but this is the process of 1. the coding of the app 2. the versioning of that code is some kind of repository 3. testing those changes 4. integrating them into the app if those tests are passed 5. And then that continuous process of releasing those changes into production
So for the CI/CD process to work and specifically to work quickly - we will need some level of automation as we move through that cyclical process. You don’t want to have to pause things to get approval or manually change things when tests pass - you want it to get to the user as quickly as possible after everything has been tested.
The next piece is reproducibility . You have different teams working on different pieces of the puzzle, but at the end of the day the end result is the same. Everyone is working on that same app - in this case our stock platform. So as jobs go from one team to another team and as your app goes from development to testing to finally your users, you want to make sure that there’s a common ecoystem that everyone is working in. When you’re testing your app you want to make sure that your environment is as similar to what is going to be in real-life or what is called “production”. You also want to make sure that your code itself is reproducible and that it works for users regardless of their location or their computer or their browser maybe.
The last piece that I find really interesting is the concept of culture change . So what needs to change in your organization so that you’re able to function while still holding this tension or conflict between speed and stability. How do you make sure that teams that have different incentives - for example security team vs. a data team - are able to work together.
So let me pause - that’s a lot - everyone got a bit of a history lesson but as far as i’m aware no one here is a software developer or an IT engineer. So that brings me to this very important question: But
Why should we as data scientists care about this?
Has this ever happened to you?
You come back to code from a year ago and now it doesnt run!
You need to hand off your model to the Engineering team but they only code in Java
Continuous Integration & Delivery & Collaboration
Your boss asks you to share that Shiny app with a client but the ops team is too busy working on their roadmap to help you deploy it somewhere.
We should care because …
Data scientists are developers!
Data science careers have moved from academic sphere to tech and software but education hasnt always followed
Automation, collaboration, testing can dramatically improve data work and improve reproducibility
The many hats of a data scientist
Improve collaboration & communication with other teams
spent a lot of time talking about teams working together to create a shared product. Data scientists are a part of that team. DS is a relatively new field and creating data-intensive apps is a huge part of tech world today.
DS career paths started in academia - not a lot of best practices are taught
Responsibility of the analyst
I mentioned before that a lot of DS comes from academia and research. So the concept of reproducing your results - especially if those results play a role in how medicines or medical devices are developed - is incredibly important.
2005 essay by John Ioannidis in scientific journal on what is known as the replicability crisis in scientific publishing, arguing that majority medical research studies cannot be replicated.
So as data scientists and we are curators of the data and are responsible for its legitimacy in many ways - obv cant always control it of course.
This second paper started looking a method of reproducing results - namely Jupyter notebooks - and found a lot of ways that reproducibility was improved but also a lot of places where things could have been done better and some best practices for how to do that - in what we call literate programming.
27,271 Notebooks:
11,454 could not declare dependencies
5,429 could not successfully install declared dependencies
9,185 returned an error when ran
324 returned a different result than originally reported
Let’s get back to our principles:
The Devops Process Flow
The CI/CD Pipeline
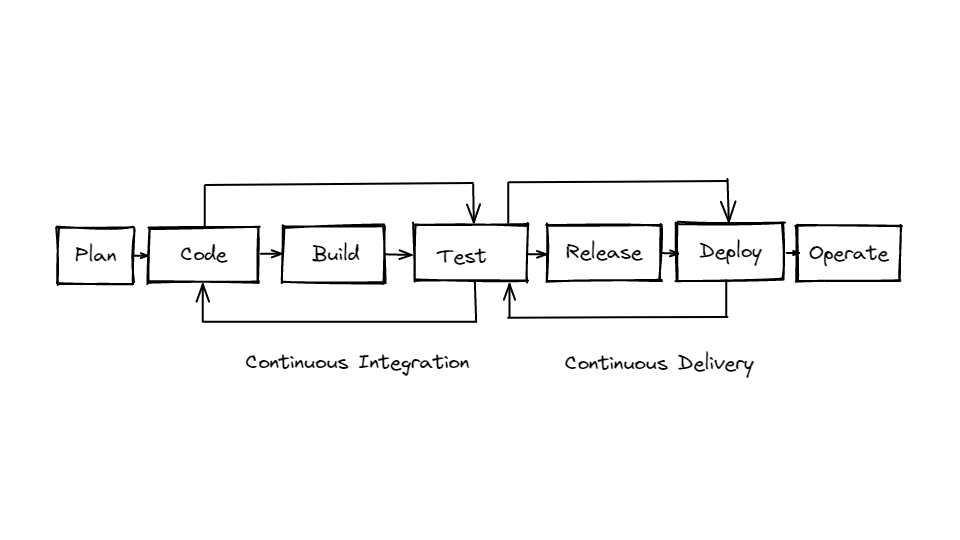
As we discussed before CI/CD is an iterative cycle of small steps to quickly build, test, and deploy your code - this is a critical component of devops.
So CI/CD is often said in the same breath - as it makes up a continuous pipeline - but its actually pretty discrete parts so I want to make sure we understand how they differ.
-Continuous integration (CI) - this is where you or anyone who writes code, automatically builds, tests, and commits code changes into a shared repository; This is usually triggered by an automatic process where the code is built, tested and then either passes or fails. This step is focused on improving the actual build or application as quickly as possible.
Different types of tests - from unit tests to integration tests to regression tests.
-Continuous delivery (CD) and deployment are less focused on the build but on the actual installation and distribution of your build. This includes an automated process to deploy across different environments - from development to testing and finally to production. Delivery is the process for the final release - that “push of a button step” to get to prod.
we’ll talk about some examples of popular CI/CD tools in a bit - Github Actions, Jenkins, CircleCI, Gitlab CI
Environment Management
as similar to prod as possible
unit & integration testing
data validation
“sandbox” with data that’s as close to real as possible
automatic CD
isolated from dev & test
created with code
unit test - testing individual units of code to make sure it does what you want it to do
integration test - make sure putting pieces together doesnt introduce any errors
want to be able to reproduce the environments as closely as possible
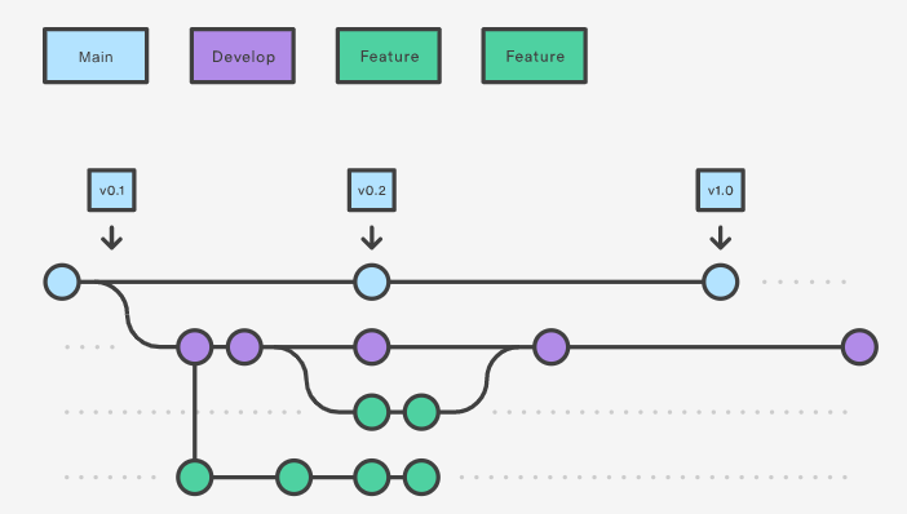
Version Control & Workflows
Version control is a main tool for Continuous Integration -
lots of variants - git, github., svn, gitlab, etc
distributed version control - everyone has their own repo
can track changes and roll them back
can fix merge conflicts
an an iterative process to build, test, collaborate on your code to above environments. Very commonly, individuals work on separate branches that are then tested and reviewed by colleagues before they are merged into a main branch.
In addition to the action of promoting your code - its also important to have processes in place for how the code integration process occurs - includes humans coming together and making some decisions -
e.g code reviews, process for your team, how to name things, pull requests, merging, feature branching, automatic tests
Lab Activity - developing locally using Quarto
🟥 - I need help
🟩 - I’m done
Login to pos.it/class with code devops_workshop
Lab 1 Part 1
Is version control secure?
A short auth teaser
We can use a variety of data sharing “transfer protocols”
Protocols specify what kind of traffic is moving between 2 machines
Use different security mechanisms
Ports on the host and destination specifies where to direct the traffic
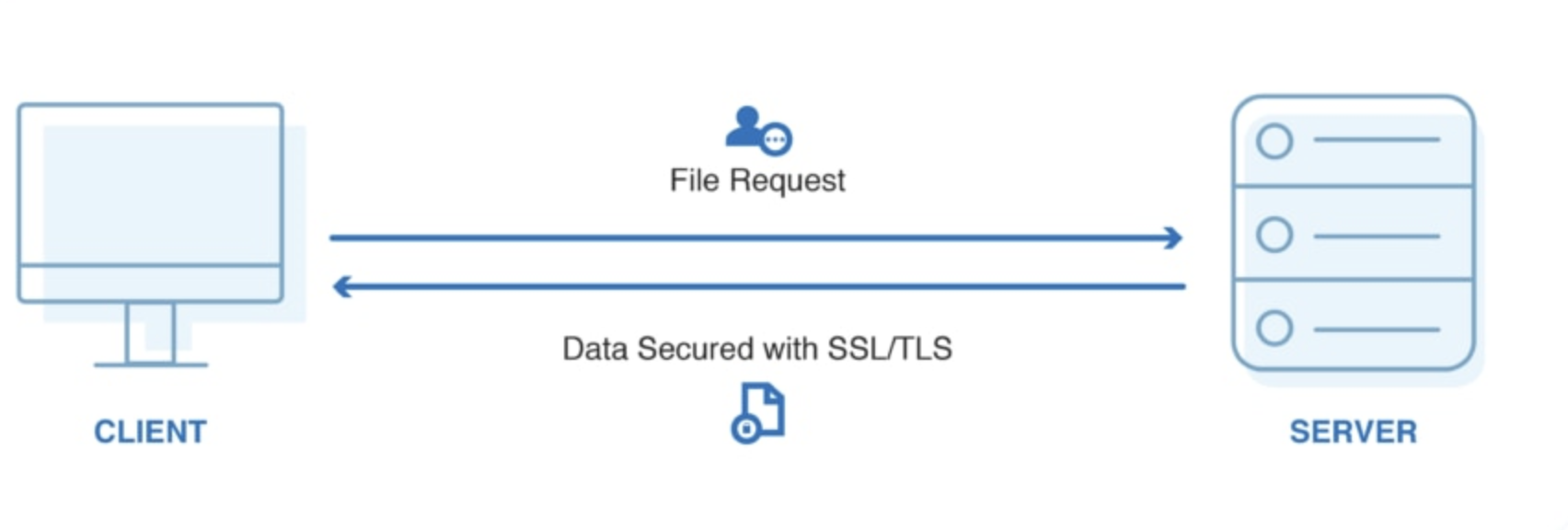
HTTPS
Add diagram - http and https two computers with ports
There are lots of diff transfer protocols; what you use depends on what kind data is being transferred and your security requirements. So for example, maybe you’re sending plain text or email or a webpage.
Protocols as well as processes or application run on specific ports. A port is a virtual point where network connections start and end. Allow computers to easily differentiate between different kinds of traffic. So for example, Shiny Server runs on port 3838, Workbench runs on 8787
whether its email, text, files, etc Ports are software-based and managed by a computer’s operating system. Ports emails go to a different port than webpages, for instance, even though both reach a computer over the same Internet connection.
Git protocol options
http - 80
https - 443
ssh - 22
we’ll be using https - because … from jenny bryans happy git with R
I find HTTPS easier to get working quickly and strongly recommend it when you first start working with Git/GitHub.
HTTPS is what GitHub recommends, presumably for exactly the same reasons.
The “ease of use” argument in favor of HTTPS is especially true for Windows users.
Another advantage of HTTPS is that the PAT we’ll set up for that can also be used with GitHub’s REST API.
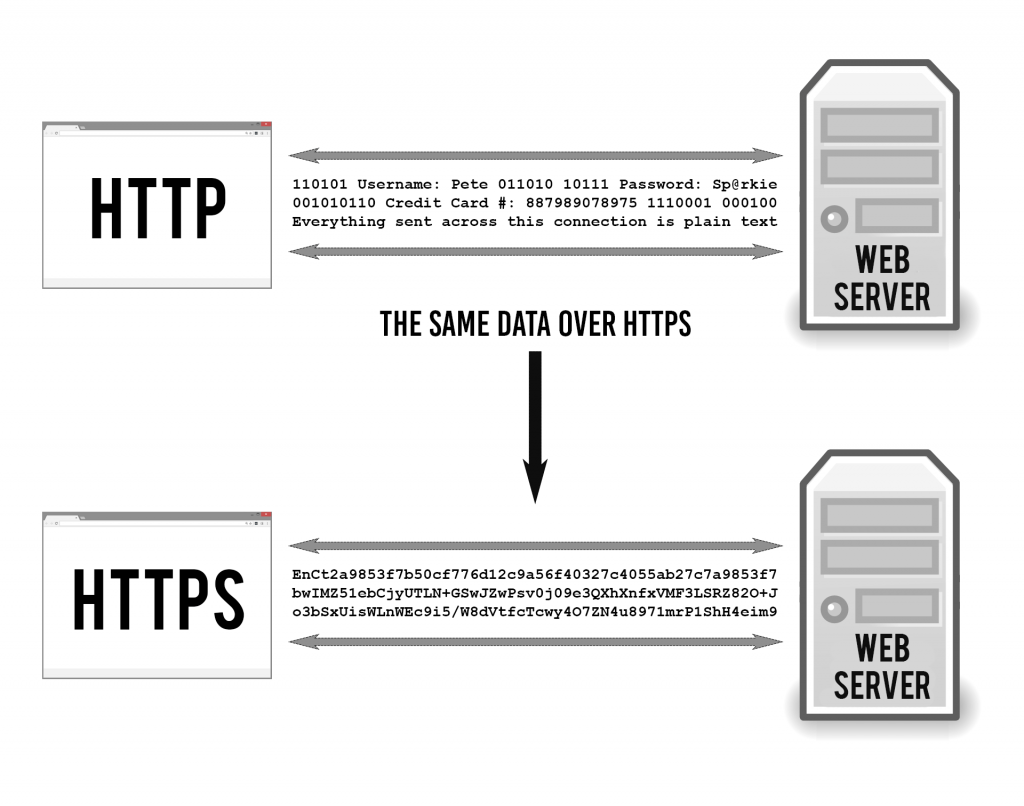
hypertext transfer protocol When a web user wants to load or interact with a web page, their web browser sends an HTTP request to the origin server that hosts the website’s files. These requests are essentially lines of text that are sent via the internet.
https : http encrypted with SSL/TLS - digital certificates that establish an encrypted connected
SSH: secure shell, public-key cryptography to authenticate the client, used for remote logins, command line execution
HTTPS is simpler. For most services besides Github, you just have to enter in your username and password, and you’ll be able to push and pull code.
You don’t have to juggle multiple SSH keys around to use multiple devices.
Port 443, which HTTPS uses, is open in basically any firewall that can access the internet. That isn’t always the case for SSH.
The primary downside for most people is that you must enter your Git password/token every time you push. While it gets added to a cache, it’s not configured to cache permanently (though this can be changed). With SSH keys, it just uses the key file on disk every time.
Where SSH takes the lead is with the authentication factor—the key. The length of it alone makes it harder to accidentally leak, and due to it being unwieldy and unique, it’s generally more secure.
Reproducing your environment
What are the layers that need to be reproduced across your dev, test, and prod environments?
What’s your most difficult reproducibility challenge?
Layers of reproducibility
code - scripts, configs, applications
Packages
System - r and python depend on underlying system software - for example, spatial analysis packages, or anything that requires Java - rJava
OS
Hardware - processors Intel chip, silicon chip
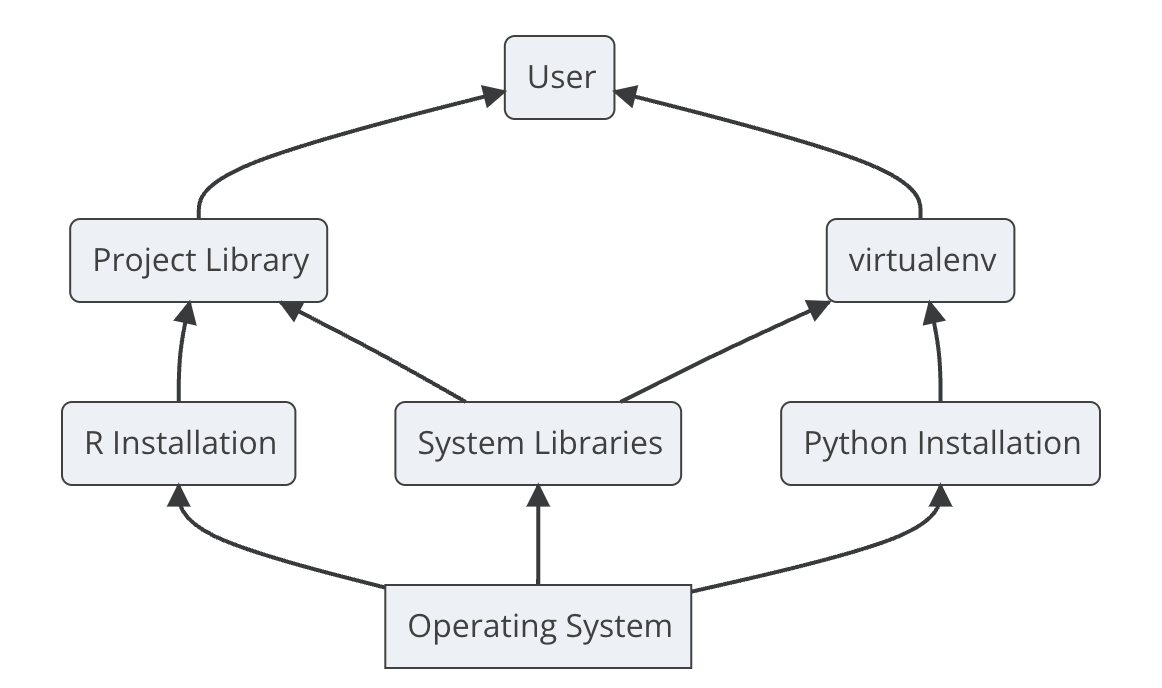
Packages vs. Libraries vs. Repositories
Package - contains code, functions, data, and documentation.
Library - is a directory where packages are installed.
Repository - a collection of packages. CRAN is a public external repository that is a network of servers that distribute R along with R packages.
packages - Can be be distributed as SOURCE (a directory with all package components), BINARIES (contains files in OS-specific format) or as a BUNDLE (compressed file containing package components, similar to source).
library - You can have user-level or project-level libraries. Run .libPaths() to see yours. To use a package in has to be installed in a library with install.packages() and then loaded into memory with library(x) .
repo - others include pypi, bioconducter, private repos
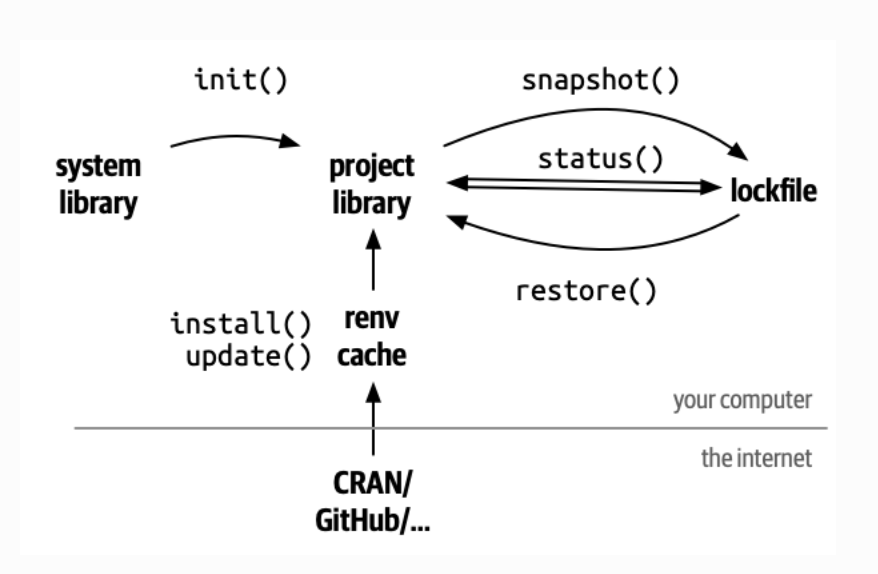
renv workflow
Use a version control system e.g.git with GitHub
One user (should explicitly initialize renv in the project, This will create the initial renv lockfile, and also write the renv auto-loaders to the project’s .Rprofile and renv/activate.R. These will ensure the right version of renv is downloaded and installed for your collaborators when they start in this project.
push your code alongside the generated lockfile renv.lock. Be sure to also share the generated auto-loaders in .Rprofile and renv/activate.R.
After this has completed, they can then use renv::restore()
Example - renv
# install.packages("renv")
renv::init()
renv::snapshot()
lapply(.libPaths(), list.files)
Lab Activity - renv workflow & github authentication
🟥 - I need help
🟩 - I’m done
Lab 1: Part 2 & 3
You’ll be doing renv in your workbench environment both in your console for r code and in the terminal for git commands you’ll also need to log in to your github account where you’ll be creating an upstream repository to link with your local code.
we’ll be using https auth but there’s also information if you later want to test out ssh
10-15 minutes
Power of YAML
YAML Ain’t Markup Language
communication of data between people and computers
human friendly
configures files across many execution environments
YAML
EmpRecord:
emp01:
name: Michael
job: Manager
skills:
- Improv
- Public speaking
- People management
emp02:
name: Dwight
job: Assistant to the Manager
skills:
- Martial Arts
- Beets
- Sales
whitespace indentation denotes structure & hierarchy
Colons separate keys and their values
Dashes are used to denote a list
Example - YAML in action
Docker compose yaml file to spin up all 3 Posit Pro products
Exercise - Inspect your YAML
🟥 - I need help
🟩 - I’m done
Inspect your _quarto.yml file and identify what each part of it does using the quarto site.
Continuous Integration Example
today - we’ll be discussing GHA Actions - which is a common CI tool that is handy because it uses the same platform as your versioned repositories - inthis case github
uses yaml as a configuration tool
Other GHA Categories
Deployment
Security
Continuous Integration
Automation
Pages
Make your own!
Examples
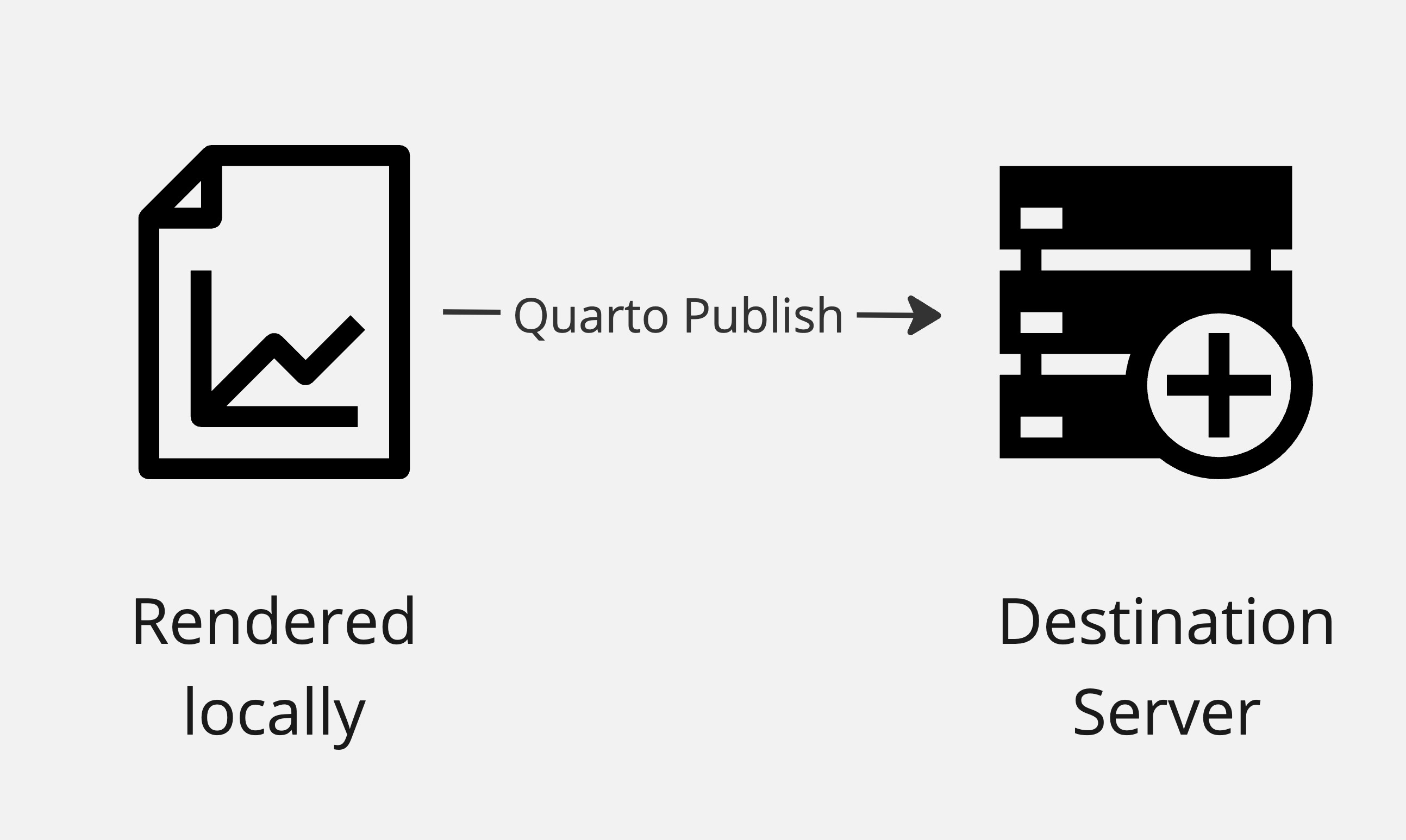
Quarto Publish Flows
Manually
Continuous Integration
can publish to quarto pub, GHP, connect, netlify, confluence, other destinations, more work to set up
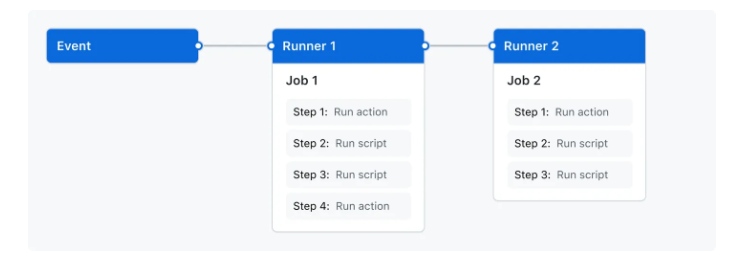
GHA Structure
Open source ecosystem of available actions
Workflows can include tests, markdown renders, shell scripts, cron jobs, or deployments. They can be as simple or as complicated as you need. Open-source community provides a ton of examples of actions.
Lab Activity - CICD with Github Actions
🟥 - I need help
🟩 - I’m done
Lab 1: Part 4
we’ll be doing a few things - create a gh branch - publish to github - create a gha with a yaml file - create an api key for connect - update yaml file - push everything
Logging
import logging# Configure the log object format = ' %(asctime)s - %(message)s ' ,= logging.INFO# Log app start "App Started" )
# Configure the log object <- log4r:: logger ()# Log app start :: info (log, "App Started" )
create a log session for your r or python code, write a log statement, gets added into an entry
what to log
types of logs
Monitoring
Prometheus
Grafana
Part 3: Docker for Data Scientists
Section Goals
to understand different docker workflows
to learn common docker syntax for building and running containers
to get hands on experience building and running containers
to explore the linux file system
Why use a container at all?
allows you to package up everything you need to reproduce an environment/application
lightweight system without much overhead
share containers with colleagues without requiring them to have to set up their own local machines
quick testing and debugging
allows you to easily version snapshots of your work
scaling up
Our Docker Environment
Workflow
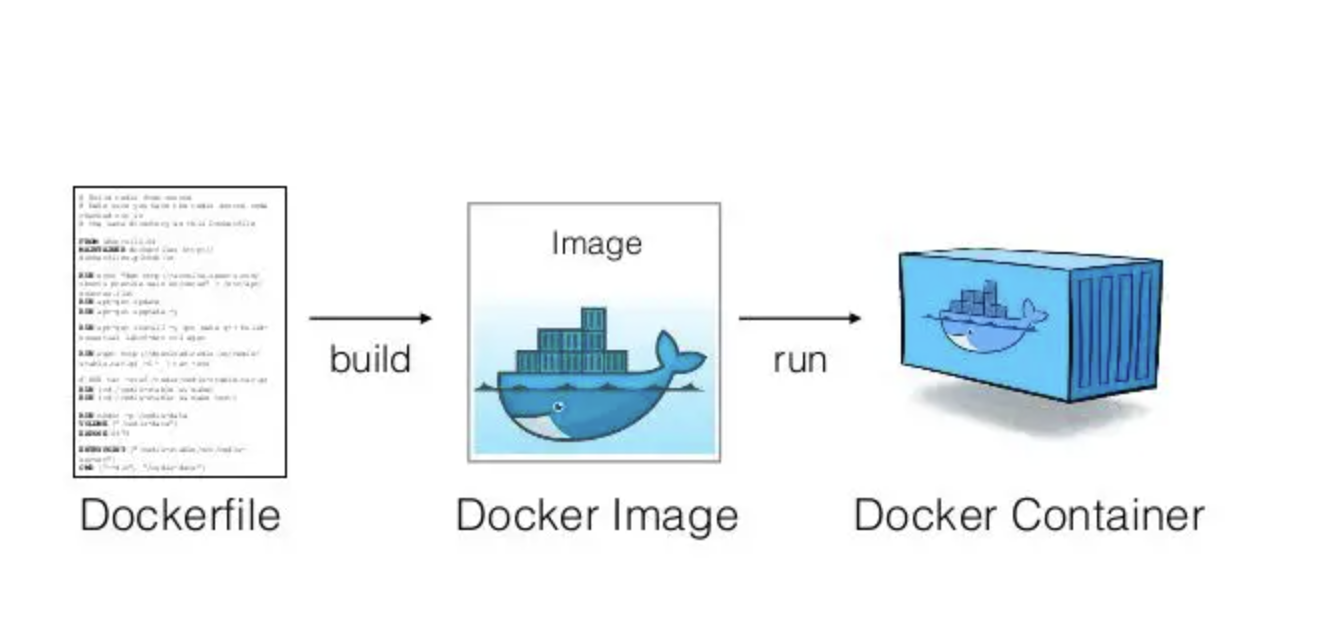
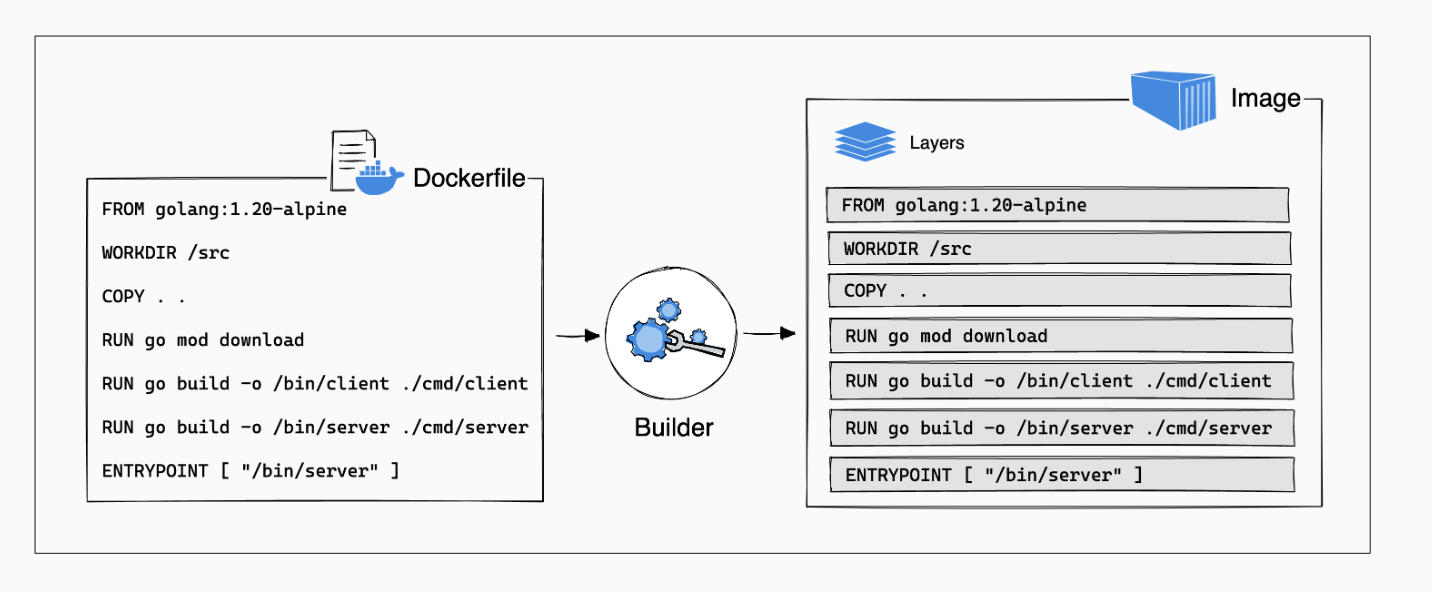
dockerfile - is a script of instructions for how to build an image
image - everything you need to run an application - all the layers that build the environment, dependencies, libraries, files
container - isolated instance of a running image. you can create, stop, start, restart, containers. When a container is removed/deleted any changes to its state that arent stored in some kind of persistent storage disappear. Called ephemeral container - Think of a container as a snapshot in time of a particular application.
Missing piece - repository - for images, like dockerhub, container registry cloud services, private registries
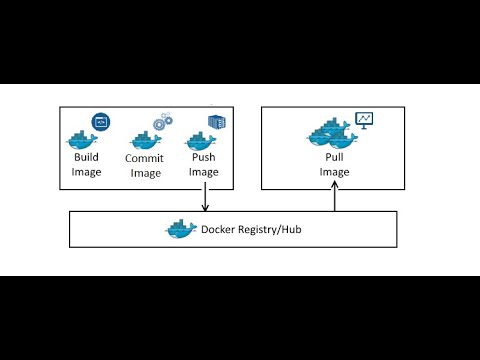
Build - Run - Push
Architecture
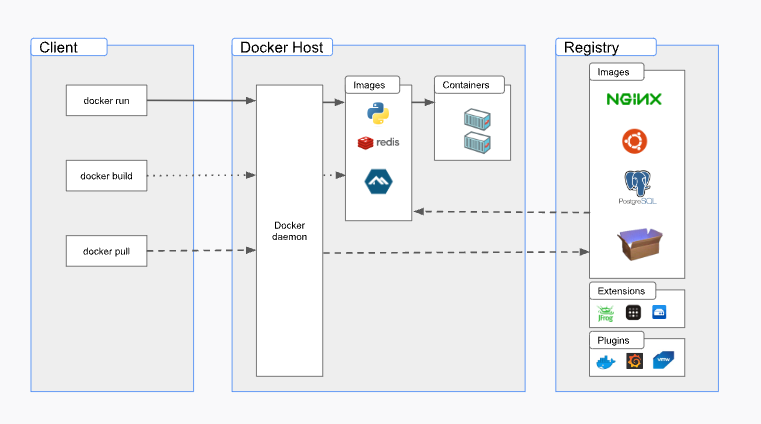
On the left we have the client - think of this as your computer or perhaps a computer somewhere in the cloud
on the right you have the server - this the docker host which runs something called the Docker daemon - you’ll be communicating with the Docker daemon via a command line interface.
The host can be remote or it can be on your computer with the client - so for example, you can download something called Docker Engine. In most cases the host is running on a Linux OS. (in different laptop OS, Docker Desktop uses a lightweight VM under the hood)
Docker engine is a container runtime that runs on different OS’s. Sets up the isolated environment for your container.
what the heck is the Docker daemon - its a service that does all the heavy lifting of building and running your containers
registry - upload and download images
Docker Desktop includes the Docker daemon (dockerd), the Docker client (docker), Docker Compose - another client, Docker Content Trust, Kubernetes, and Credential Helper.
Images
made up of individual layers so its really quick to build isolating applications into their own image
Dockerhub Registry
https://hub.docker.com/search?q=
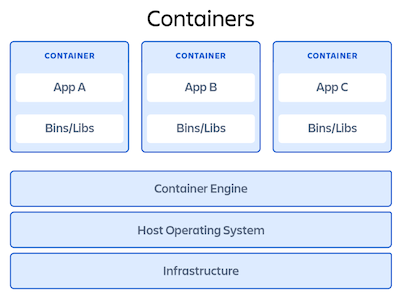
Containers
runnable instance of an image.
From the bottom up Containers run on some sort of infrastructure - this could be your laptop or a server somewhere in the cloud
host OS - shared OS between container instances, dont need a guest os for each one, makes them really light and able to spinup in milliseconds
containers are very lightweight which makes it really easy and quick to spin them up
Instead, the Docker daemon communicates directly with the host operating system and knows how to ration out resources for the running Docker containers.
How can data scientists use docker?
Example - testing & versioning
docker pull postgres:12docker pull postgres:latestdocker image ls -a docker run -d -e POSTGRES_PASSWORD=mysecretpassword --name postgres_early imageIDdocker run -d -e POSTGRES_PASSWORD=mysecretpassword --name postgres_new imageIDdocker container ls -a docker stopdocker restart
can pull but also if you just run - will put it from hub if doenst find locally Let’s see an example of what this looks like in practice. Lets say we need to use a postgres sql database for some testing - but we want to test using an older and a newer version of postgres.
docker image ls - lets list all the images that we have
docker pull postgres:12 - see how its pulling and extracting all these layers - but what if we want a newer version or what if we need to run both versions on our machine
docker pull postgres:latest - notice how some of these layers already exist so it takes a lot less time
Example - reproduce environments
https://hub.docker.com/u/rocker
# pull the image
docker pull rocker/r-base
# run container
docker run --rm -it rocker/r-base
Example - isolate applications
https://hub.docker.com/u/rstudio
DO NOT RUN!
docker run -it --privileged \
-p 3939:3939 \
-e RSC_LICENSE=$RSC_LICENSE \
rstudio/rstudio-connect:ubuntu2204
Example - Docker as deployment strategy
https://github.com/mickwar/ml-deploy
Example - Docker in CI pipeline
jobs:
build:
runs-on: ubuntu-latest
steps:
-
name: Checkout
uses: actions/checkout@v3
-
name: Login to Docker Hub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
-
name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
-
name: Build and push
uses: docker/build-push-action@v4
with:
context: .
file: ./Dockerfile
push: true
tags: ${{ secrets.DOCKERHUB_USERNAME }}/latest
Data scientists benefit from Docker’s consistency and reproducibility.
Create isolated environments for different experiments.
Share work with colleagues without environment setup issues.
Consistency: Containers ensure that applications run the same way across different environments.
Isolation: Containers isolate applications and their dependencies, preventing conflicts.
Portability: Containers can run on any system that supports Docker, reducing “it works on my machine” issues.
Modes for running containers
Detached
docker run -dThis runs the container in the background so the container keeps running until the application process exits, or you stop the container. Detached mode is often used for production purposes.
Interactive + terminal
docker run -itThis runs the container in the foreground so you are unable to access the command prompt. Interactive mode is often used for development and testing.
Remove everything once the container is done with its task
docker run --rmThis mode is used on foreground containers that perform short-term tasks such as tests or database backups. Once it is removed anything you may have downloaded or created in the container is also destroyed.
Run Command
Lab Activity - Running containers
🟥 - I need help
🟩 - I’m done
Lab 2: Part 1
Running containers
docker pull ubuntu
docker image ls -a
docker run -it ubuntu bash
ls
whoami
hostname
# exit the container with Ctrl+D or exit
docker run -d ubuntu
docker container ls -a
docker run -d -P --name nginx1 nginx:alpine
docker container stop nginx1
docker run --rm debian echo "hello world"
Nginx, pronounced like “engine-ex”, is an open-source web server that, since its initial success as a web server, is now also used as a reverse proxy, HTTP cache, and load balancer.
Container Debugging
docker run -it -d ubuntu
docker container ls -a
docker exec -it CONTAINER_ID bash
docker container run -d --name mydb \
--name mydb \
-e MYSQL_ROOT_PASSWORD=my-secret-pw \
mysql
docker container logs mydb
Lab Activity - Debugging Containers
🟥 - I need help
🟩 - I’m done
Lab 2: Part 2
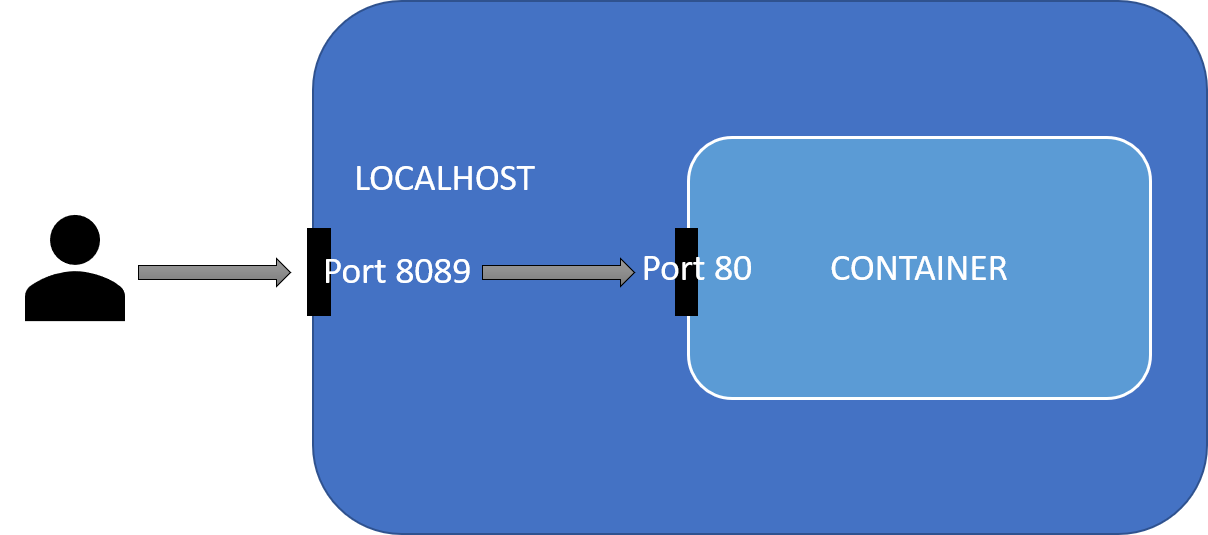
Port Mapping with docker run -p host:container
docker pull httpd:alpine
docker pull httpd:latest
docker inspect --format='{{.Config.ExposedPorts}}' httpd:latest
docker inspect --format='{{.Config.ExposedPorts}}' httpd:alpine
docker run -p DockerHostPort:ApplicationPort
docker run -d -p 80:80 --name httpd-latest httpd:latest
curl http://localhost:81
docker run -d -p 6574:80 --name httpd-alpine httpd:alpine
curl http://localhost:80
Lab Activity - Mapping ports
🟥 - I need help
🟩 - I’m done
Lab 2: Part 3
Persisting data with Docker
State is persistent information that is recorded and recalled later
Containers are designed to be ephemeral e.g. stateless by default
Data applications are usually stateful and more complex to deploy
Images are made of a set of read-only layers. When we start a new container, Docker adds a read-write layer on the top of the image layers allowing the container to run as though on a standard Linux file system.
So, any file change inside the container creates a working copy in the read-write layer. However, when the container is stopped or deleted, that read-write layer is lost.
Lab Activity - Persisting Data
🟥 - I need help
🟩 - I’m done
Lab 2: Part 4
Building Docker Images
Images are build using a Dockerfile or interactively “on-the-fly” for testing
Build Command
Lab Activity - Commit and push container to DockerHub
🟥 - I need help
🟩 - I’m done
Lab 2: Part 5
A few Dockerfile Build Commands
ARG
Define variables passed at build time
FROM
Base image
ENV
Define variable
COPY
Add local file or directory
RUN
Execute commands during build process
CMD
Execute command when you run container; once per Dockerfile
ENTRYPOINT
Execute command to change default entrypoint at runtime
USER
Set username or ID
VOLUME
Mount host machine to container
EXPOSE
Specify port pn which container listens at runtime
Dockerfile Example
Walk through Posit Connect Dockerfile
Activity - Putting it all together in Dockerfile
🟥 - I need help
🟨 - I’m still working
🟩 - I’m done
Complete Lab 2: Part 5
Part 4: Data Science in Production
Data Science in Production
Production “State”
What are some questions that we should ask once our code is ready for production?
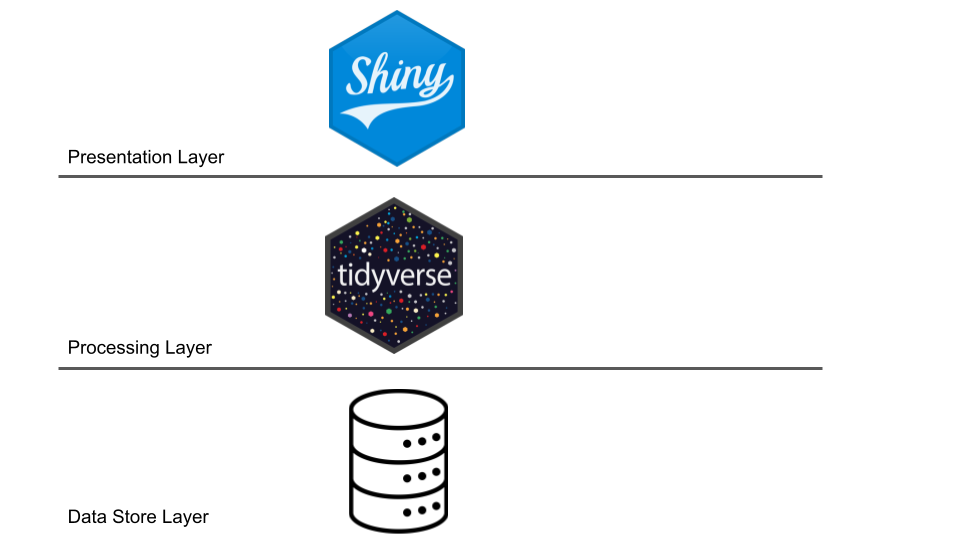
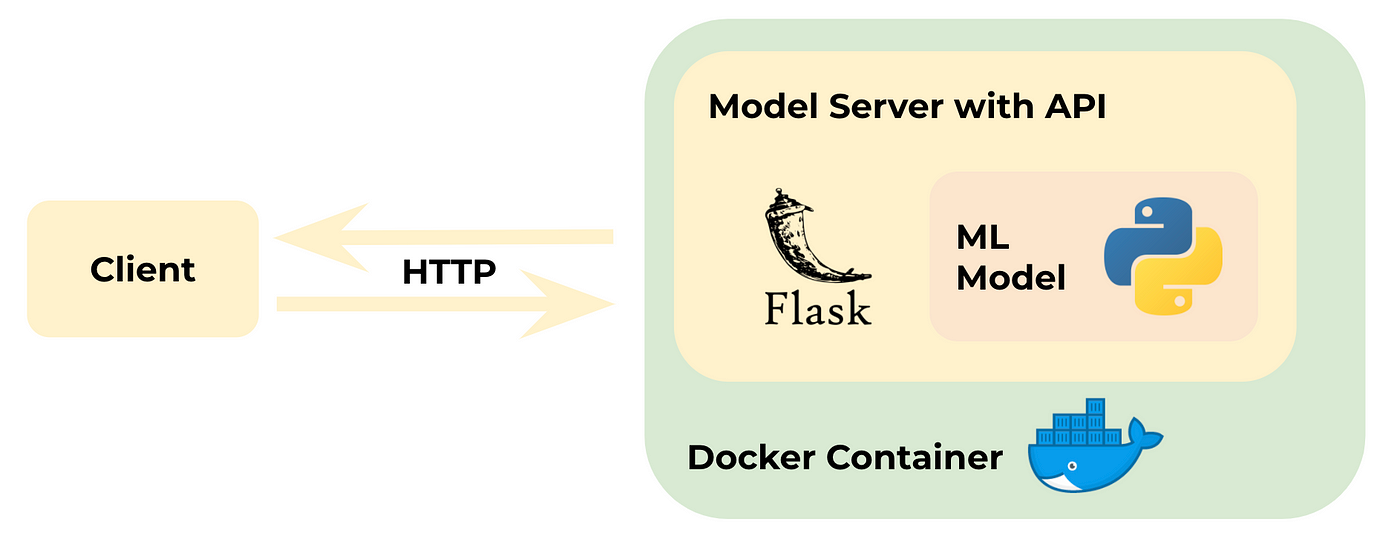
Choosing the right presentation layer
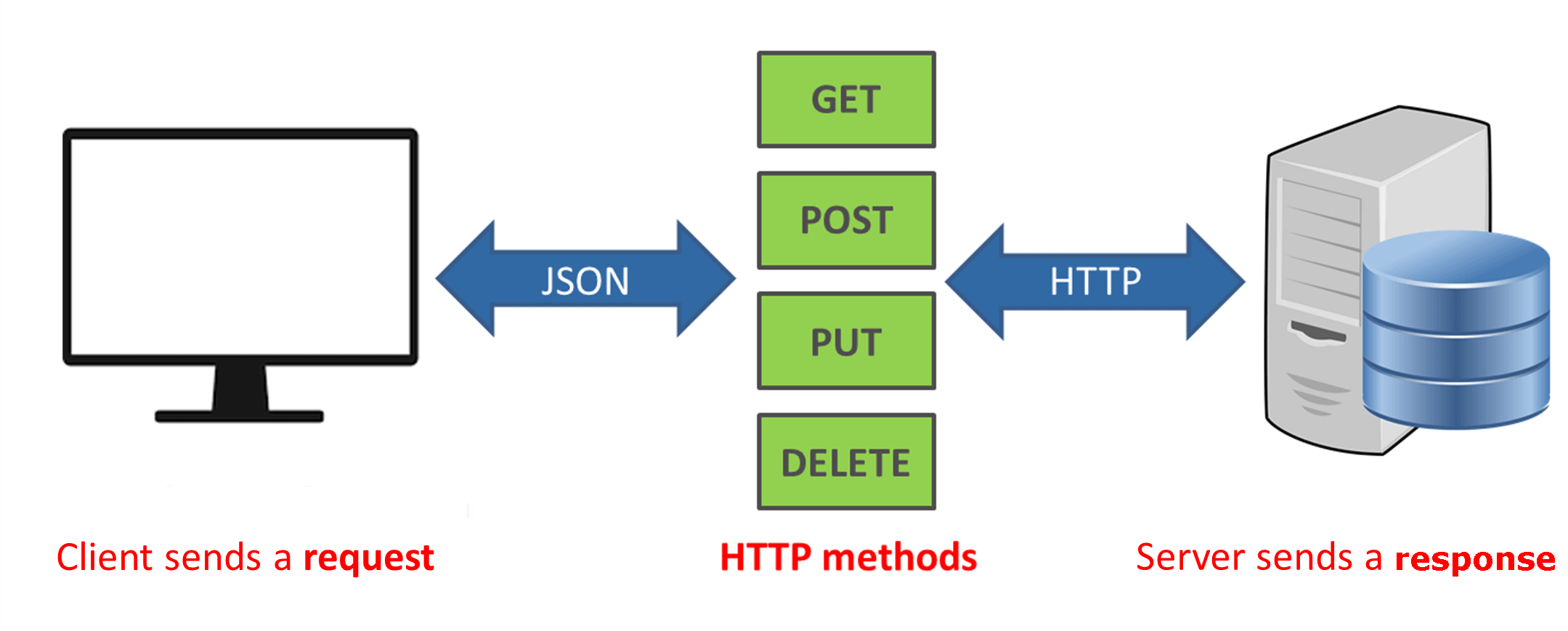
Choosing a REST API
application programming interface clients to communicate with a server. Rest API is a kind of web-service which stores and retrieves necessary data. It provides great flexibility to developers since it does not need any dependent code libraries to access the web-services. Amongst the many protocols supported by REST, the most common one is HTTP. When a request is sent from the client using a HTTPRequest, a corresponding response is sent from the server using HTTPResponse.
Lab Activity: Host API on Posit Connect
🟥 - I need help
🟩 - I’m done
Lab 3: Part 1
Lab Activity: Explore API structure
🟥 - I need help
🟩 - I’m done
Lab 3: Part 2
Lab Activity: Explore Plumber
🟥 - I need help
🟩 - I’m done
Lab 3: Part 3
Where is it deployed?
Lab Activity: Access API data
🟥 - I need help
🟩 - I’m done
Lab 3: Part 5










.jpg)
.jpg)



.png)
-01.png)